
Kontakt
- Let’s connect!
- +49 (0)931 780998-87
- hello@ososoft.de
- Kontaktformular


25.02.2022 | Adrian Wettklo
Daten in SAP Systeme zu integrieren ist eine nicht zu vernachlässigende Aufgabe, die es in den verschiedensten Szenarien und Projekten zu bewältigen gilt. Dies zunehmend auch im Kontext von Big Data und mit ungewöhnlichen Datenquellen. SAP allein bietet inzwischen bereits verschiedene Lösungen in diesem Bereich an und die Entscheidung, welche hier für die jeweiligen Anforderungen einzusetzen ist, ist gründlich abzuwägen. Denn ohne eine verlässliche Datenbasis bringt auch die beste Anwendung nur wenig Nutzen. SAP Data Services (DS) haben wir bereits in anderen Blogbeiträgen behandelt, nun soll auf HANA Smart Data Integration (SDI) eingegangen werden.
Hana SDI ermöglicht große Mengen an Daten aus verschiedensten Quellen für (ausschließlich) HANA Datenbanken zu integrieren und zu transformieren. Erschienen im Jahr 2013 ist SDI Teil des HANA Softwarepaktes. Trotz einiger Flexibilität ist es nicht als Ersatz, sondern als Ergänzung zu den anderen Integrationstechnologien der SAP zu sehen. In diesem Rahmen deckt SDI jedoch sowohl klassische ETL Prozesse als auch Echtzeit Replikationen ab. Im ersten Fall müssen große Datenmengen im Batch geladen und dabei transformiert bzw. verdichtet werden (für zum Beispiel Analysen im BI Kontext), im anderen Fall wird die Datenquelle ständig überwacht und Datenänderungen direkt auf HANA übertragen (wenn beispielsweise Tabellen aus einem SAP System in ein anderes repliziert werden). Diese Aufgaben sind in SDI aber nicht strikt getrennt, Transformationen sind in simplerer Form auch für Echtzeit-Übertragungen möglich. Die Daten können dabei aus unterschiedlichen Quellen stammen, wie etwa folgende:
Diese werden über mitgelieferte Adapter angebunden und es besteht auch die Möglichkeit, eigene Adapter für zusätzliche Quellen zu implementieren.
SDI basiert auf SAP Smart Data Access. Dies erlaubt die zu integrierenden Daten für HANA zugänglich zu machen, ohne diese physisch speichern zu müssen. Die externe Datenquelle wird als sogenannte Remote Source angebunden, diese definiert die allgemeinen Einstellungen. Der Zugriff erfolgt über virtuelle Tabellen, die sich dabei identisch zu lokal vorhandenen verhalten. Bei SDI wird allerdings eine tatsächliche Übertragung in den HANA Speicher durchgeführt. Hierzu werden solche virtuellen Tabellen zu einer Remote Source angelegt und abgefragt.
Werden SAP-Daten repliziert, geschieht dies auf Ebene der einzelnen Tabellen und nicht objektorientiert (zum Beispiel für Auftrag oder Bestellung). Ein solides Verständnis der Datenstrukturen ist also notwendig.
Die Komponenten von HANA SDI sind grundsätzlich für alle Einsatzszenarien die gleichen, hier dargestellt ist der der on-Premise Fall:
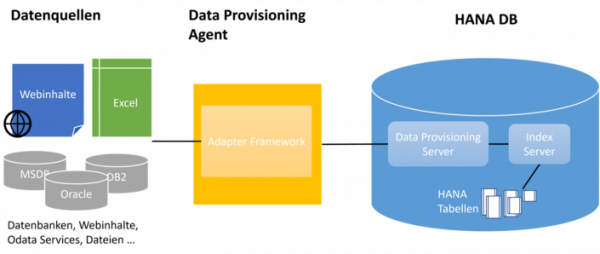
Die einzelnen Komponenten nehmen dabei folgende Rollen ein:
Die Architektur ist allgemein skalierbar, somit sind per SDI auch Szenarien mit zahlreichen Tabellen, großem Übertragungsvolumen und hohen Anforderungen an Verfügbarkeit realisierbar.
Die Einrichtung der Replikationen findet auf der HANA DB statt. Die Konfiguration HANA-seitig erfolgt über die WEB IDE, HANA XS Studio und die HANA Web-based Development Workbench. Je nach Quelle müssen auch dort im Vorab Konfigurationen durchgeführt werden. Die Umsetzung erfordert also Kenntnisse zu HANA und der Datenquelle. Für gewöhnliche Aufgaben muss praktisch kein Coding erstellt werden.
Aktive Replikationen können über im Browser laufenden Monitoren überwacht und administriert werden. Konfigurierbare Benachrichtigungen per E-Mail informieren Administratoren zu aufgetretenen Fehlern.
Grundsätzlich gibt es zwei verschiedene Arten, wie Replikationen mit SDI umzusetzen sind - Replication Tasks und Flowgraphs.
Replication Tasks
Sollen Daten direkt und ohne (tiefergreifende) Transformation übertragen werden, bietet sich der Einsatz von Replication Tasks an. Sie sind hierfür optimiert und relativ unkompliziert einzurichten. Betrachten wir beispielsweise den gängigen Fall, dass eine Tabelle aus einer nicht SAP Datenbank komplett und in Echtzeit repliziert werden soll:
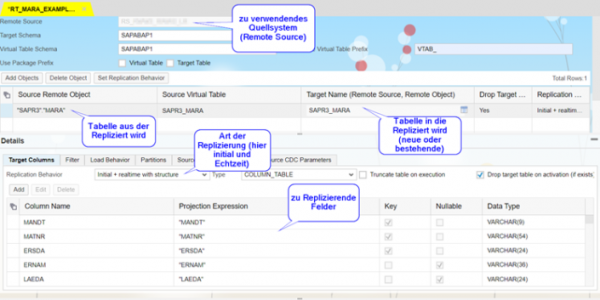
Zuerst wird das zu replizierende Remote Objekt aus der zugehörigen Remote Source ausgewählt. Dazu werden die nötigen Felder spezifiziert und die HANA-Datentypen, in die sie zu übersetzen sind, werden ausgewählt. Der zugehörige Adapter erkennt dies in der Regel eigenständig, kann aber auch im Nachgang angepasst werden. Das Replication Behavior bestimmt in erster Linie, ob Daten einmalig im Batch, beziehungsweise Änderungen laufend in Echtzeit übertragen werden sollen.
Unterstützt wird hierbei unter anderem das Partitionieren der Daten (damit wird die gesamte Datenmenge in Pakete aufgeteilt und parallel verarbeitet), oder bereits bei der Replikation nach Spaltenwerten zu filtern (analog einer WHERE Bedingung in einer SQL Anweisung). Sollen Daten ständig von der Quelle mit HANA-Tabellen synchronisiert werden, wird erst initial der aktuelle Datenstand in die Tabelle geladen und dann die Echtzeit-Replikation aktiviert. Dies lässt sich im gleichen Replication Task einrichten, Datenänderungen während dem initialen Laden werden automatisch erfasst, vorgehalten und nach Abschluss der initialen Befüllung umgesetzt. Es können statt einer ständigen Übertragung von Änderungen auch Jobs für die Übertragung im Batch eingeplant werden.
Beispiel für einen Replication Task der aus Tabelle MARA repliziert:
Flowgraphs
Flowgraphs ermöglichen gegenüber den Replicatoin Tasks ausgiebigere Transformationen der Daten, sind damit also insbesondere für ETL-Aufgaben relevant. Die einzelnen Transformationsschritte werden über grafische Elemente definiert und umfassen Funktionen wie:
Nicht alle der aufgezählten Punkte sind allerdings im Echtzeit-Kontext einsetzbar. Auch können verschiedene Datenquellen in einem Flow Graph abgegriffen werden.
Das Aufsetzen dieser Objekte ist etwas aufwändiger als die von Replication Tasks, die für Übertragungen ohne Transformationen auch bessere Performance bieten. Sie sollten also nur dann eingesetzt werden, wenn deren Funktionen auch wirklich benötigt werden.
Beispiel für einen simplen Flowgraph der aus der MARA repliziert, aber hierbei zusätzlich noch filtert und einen Join der Tabelle MBEW durchführt:
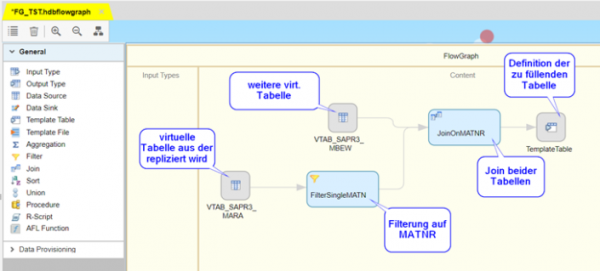
Anzumerken ist hierzu, dass Join Operationen im Echtzeit Kontext nicht unterstützt werden.
Smart Data Integration bietet für die Datenintegration auf HANA eine recht performante und vielseitige Option. Wie erwähnt stellt SDI keinen Ersatz für andere Datenintegrationstechnologien dar, es ist also weiterhin im Vorhinein abzuwägen welches Tool für den vorliegenden Anwendungsfall am besten geeignet ist. Ososoft unterstützt sie gerne mit unserem Know-How und unseren Projekterfahrung bei ihren Integrationsaufgaben.